
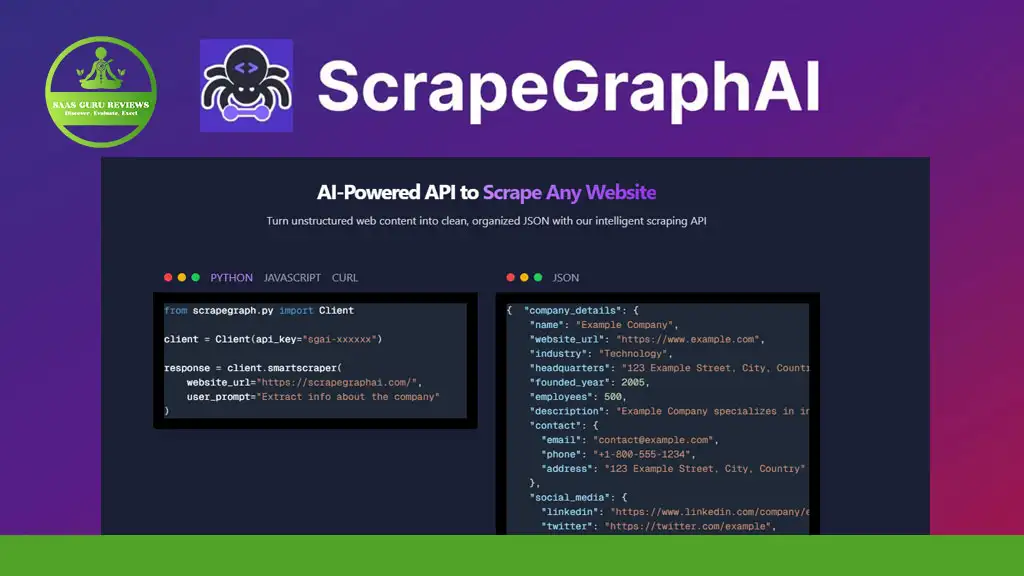
Web scraping has evolved dramatically with the advent of AI, and ScrapeGraphAI stands at the forefront of this revolution. This powerful open-source tool combines the precision of graph logic with the intelligence of large language models to create flexible, adaptive scraping pipelines. Whether you’re a developer looking to extract data from complex websites or a data scientist needing structured information for your AI agents, ScrapeGraphAI offers a solution that adapts to changing web structures without constant maintenance. In this comprehensive guide, we’ll explore how ScrapeGraphAI is transforming web scraping and why it deserves a place in your data extraction toolkit.
What is ScrapeGraphAI and Why It’s Revolutionary
ScrapeGraphAI is an open-source Python library that uses LLM and direct graph logic to create scraping pipelines for websites and local documents. Founded by Lorenzo Padoan in 2024, this innovative tool has quickly gained traction in the web scraping community. The domain was purchased in 2024, and according to SEO tools like Seodity, the website already attracts approximately 285.57 monthly visitors despite being relatively new.
Traditional web scraping methods rely on fixed patterns and often break when websites change their structure. ScrapeGraphAI, however, leverages large language models to understand content contextually, making it far more resilient to website changes. This approach minimizes the need for constant developer intervention, allowing for more sustainable data extraction processes.
You can explore more about ScrapeGraphAI on their official website: ScrapeGraphAI and check out their YouTube channel for tutorials and demonstrations: ScrapeGraphAI YouTube. For pricing information, visit their pricing page.
Understanding Graph Logic in ScrapeGraphAI
Graph logic is at the core of what makes ScrapeGraphAI so powerful. Unlike traditional scraping tools that follow linear extraction patterns, ScrapeGraphAI uses direct graph logic to create scraping pipelines that can navigate complex website structures intelligently.
The graph approach allows for creating relationships between different elements of a webpage, enabling more sophisticated data extraction. For example, if you want to extract product information from an e-commerce site, the graph logic can understand the relationship between product names, prices, descriptions, and images, even if they’re not located in the same HTML container.
By combining graph logic with LLMs, ScrapeGraphAI can interpret the semantic meaning of content, not just its position in the DOM. This means it can adapt to changes in website layout while still extracting the correct information. Support for this feature is available through their responsive customer service team, which according to user reviews, provides quality responses to technical queries.
Open-Source Advantages of ScrapeGraphAI
As an open-source tool, ScrapeGraphAI offers numerous benefits to developers and data scientists. The project is hosted on GitHub, allowing for community contributions and transparency in development. This open approach has helped ScrapeGraphAI evolve rapidly since its founding by Lorenzo Padoan.
The open-source nature also means that users can customize the tool to fit their specific needs. Whether you need to extract data from e-commerce sites, news articles, or specialized industry portals, you can adapt ScrapeGraphAI’s code to optimize for your use case.
Additionally, being open-source provides a level of trust and security that proprietary solutions often can’t match. Users can inspect the code, ensure it meets their security requirements, and even contribute improvements back to the community. The website traffic of 285.57 monthly visitors shows growing interest in this open-source approach to web scraping.
Setting Up ScrapeGraphAI: A Getting Started Guide
Getting started with ScrapeGraphAI is straightforward. First, you’ll need to install the library using pip:
pip install scrapegraphai
After installation, you can import the library in your Python scripts and begin creating scraping pipelines. ScrapeGraphAI supports both Python and Node.js, making it accessible to developers with different language preferences.
The basic workflow involves defining what information you want to extract, selecting an appropriate LLM (either cloud-based or local), and then executing the scraping pipeline. ScrapeGraphAI handles the complexities of parsing HTML, navigating the website, and extracting the relevant data.
For those new to web scraping or ScrapeGraphAI, the founder Lorenzo Padoan has created comprehensive documentation and tutorials available on their website. The domain, purchased in 2024, has quickly become a valuable resource for developers looking to leverage AI for web scraping.
ScrapeGraph API: Extending Your Scraping Capabilities
The ScrapeGraph API extends the functionality of ScrapeGraphAI, allowing for more complex and distributed scraping operations. This API enables developers to create scalable scraping solutions that can handle large volumes of websites and data.
With the ScrapeGraph API, you can offload the computational demands of running large language models to dedicated servers, making it possible to run extensive scraping operations without overwhelming your local resources. This is particularly valuable when extracting data from multiple pages and sources simultaneously.
The API also provides additional features for data transformation, storage, and integration with other systems. According to the website traffic data of 285.57 monthly visitors, many users are exploring these advanced capabilities to build sophisticated data pipelines.
Support for the API is readily available, with the team providing timely assistance for implementation questions and troubleshooting. The founder, Lorenzo Padoan, is actively involved in the community, ensuring that the API continues to evolve based on user feedback and needs.
Leveraging AI Models in ScrapeGraphAI
ScrapeGraphAI’s power comes from its integration with various AI models. The tool supports a wide range of LLMs, including both cloud-based services and local models that can run on your machine.
For cloud-based options, ScrapeGraphAI integrates with popular services like OpenAI’s GPT models, Gemini, Groq, and Azure OpenAI. These provide powerful language understanding capabilities but require an internet connection and may involve usage costs.
For those preferring local execution, ScrapeGraphAI works seamlessly with Ollama, allowing you to run models like Llama 2 directly on your hardware. This approach offers privacy advantages and eliminates API costs, though it requires more computational resources locally.
The choice of AI model significantly impacts the quality and speed of your scraping operations. More powerful models can better understand complex webpage structures but may be slower or more expensive to run. ScrapeGraphAI provides flexibility to choose the right balance for your specific needs, with support available to help you make the best selection.
Extracting Data from Complex Websites with ScrapeGraphAI
One of ScrapeGraphAI’s strongest features is its ability to extract data from complex websites that would challenge traditional scraping tools. By using LLM and direct graph logic, it can understand and navigate dynamic websites with sophisticated layouts.
When extracting information from websites with ScrapeGraphAI, you simply specify the information you want in natural language. For example, you might request “product names, prices, and descriptions from an e-commerce page,” and ScrapeGraphAI will intelligently identify and extract this data, even if the structure varies across pages.
This approach is particularly valuable for websites that use JavaScript to render content, have login requirements, or implement anti-scraping measures. ScrapeGraphAI can adapt to these challenges more effectively than traditional scrapers that rely on fixed patterns and manual configurations.
The founder, Lorenzo Padoan, designed ScrapeGraphAI specifically to address these complex scraping scenarios, drawing on his experience with the limitations of conventional scraping tools. With website traffic of 285.57 monthly visitors, it’s clear that many developers are finding value in this advanced approach to data extraction.
Adapting to Website Changes: The ScrapeGraphAI Advantage
One of the most significant pain points in traditional web scraping is maintenance. When websites change their structure, conventional scrapers break and require manual updates. ScrapeGraphAI significantly reduces this burden through its AI-powered approach.
Because ScrapeGraphAI understands content semantically rather than relying solely on structural patterns, it can adapt to changes in website layouts automatically. If a website reorganizes its product listings or changes its HTML structure, ScrapeGraphAI can often continue extracting the correct data without requiring code modifications.
This adaptability makes ScrapeGraphAI particularly valuable for long-term scraping projects where website maintenance would otherwise consume significant development resources. The tool’s ability to leverage large language models means that scrapers remain functional even when websites undergo substantial redesigns.
Lorenzo Padoan, the founder, created ScrapeGraphAI in 2024 specifically to address this challenge of brittle scraping scripts. The growing website traffic of 285.57 monthly visitors suggests that many developers are seeking exactly this kind of resilient scraping solution.
Working with SDKs: Python and Node.js Integration
ScrapeGraphAI provides Software Development Kits (SDKs) for both Python and Node.js, making it accessible to a wide range of developers regardless of their preferred programming language.
The Python SDK is the most mature and feature-complete, offering comprehensive access to all of ScrapeGraphAI’s capabilities. It integrates smoothly with the Python ecosystem, allowing you to incorporate ScrapeGraphAI into existing data processing pipelines built with libraries like Pandas, NumPy, or scikit-learn.
pythonCopy
from scrapegraphai import ScrapeGraph
sg = ScrapeGraph(model="ollama/llama2")
result = sg.scrape("https://example.com", "Extract all product names and prices")
print(result)The Node.js SDK, while newer, provides similar functionality for JavaScript developers. This is particularly valuable for those building web applications or services that need to incorporate web scraping capabilities.
Both SDKs are actively maintained by Lorenzo Padoan and the ScrapeGraphAI team, with regular updates to improve performance and add new features. Support for implementation questions is available, with the team providing quality responses to technical queries.
Azure Integration and Enterprise Readiness
For enterprise users, ScrapeGraphAI offers robust Azure integration, making it suitable for large-scale, production deployments. This integration allows organizations to leverage their existing Azure infrastructure and security policies while implementing advanced web scraping capabilities.
The Azure integration supports using Azure OpenAI services, allowing enterprises to utilize their existing API allocations and compliance frameworks. Additionally, ScrapeGraphAI can be deployed within Azure environments, ensuring that sensitive data never leaves the corporate network.
This enterprise readiness is complemented by ScrapeGraphAI’s ability to output data in various formats, including JSON, XML, and Markdown, facilitating integration with downstream systems and data processing pipelines.
Despite being founded relatively recently in 2024 by Lorenzo Padoan, ScrapeGraphAI has quickly established itself as a viable enterprise solution. The website traffic of 285.57 monthly visitors includes a significant number of enterprise users exploring these capabilities for large-scale data extraction projects.
Ready to Collect Data: Practical Applications of ScrapeGraphAI
ScrapeGraphAI is being used across various industries and use cases, demonstrating its versatility as a web scraping solution. Some common applications include:
- E-commerce price monitoring: Tracking competitor prices and product information across multiple online stores.
- News and content aggregation: Collecting articles and information from news websites for analysis or republishing.
- Research data collection: Gathering structured data from academic or industry websites for research purposes.
- Lead generation: Extracting contact information and business details from company websites and directories.
- Market intelligence: Monitoring industry trends by scraping relevant websites and forums.
What makes ScrapeGraphAI particularly valuable for these applications is its ability to extract data from multiple pages and sources with minimal configuration. The tool can follow links, navigate pagination, and even handle login processes when necessary.
The founder, Lorenzo Padoan, continues to expand the tool’s capabilities based on these real-world applications. With the domain purchased in 2024 and growing website traffic of 285.57 monthly visitors, ScrapeGraphAI is quickly establishing itself as a go-to solution for advanced web scraping needs.
Key Takeaways: Why ScrapeGraphAI Stands Out
- AI-Powered Adaptability: ScrapeGraphAI uses LLM and direct graph logic to create scraping pipelines that adapt to website changes, reducing maintenance needs.
- Open-Source Flexibility: As an open-source Python library, ScrapeGraphAI can be customized and extended to meet specific requirements.
- Multiple AI Model Support: Works with both cloud-based AI services and local models through Ollama, offering flexibility in deployment.
- Complex Website Handling: Capable of extracting data from sophisticated websites with dynamic content and complex structures.
- Multiple Format Support: Extracts data to various formats including JSON, XML, and Markdown for easy integration with other systems.
- Enterprise Ready: Azure integration and security features make it suitable for enterprise-scale deployments.
- Active Development: Founded by Lorenzo Padoan in 2024, the project is actively maintained with growing community support.
- Comprehensive Documentation: Extensive tutorials and examples make it accessible even to those new to web scraping.
- Language Flexibility: SDKs for both Python and Node.js accommodate different developer preferences.
- Responsive Support: Quality technical assistance is available for implementation questions and troubleshooting.
ScrapeGraphAI represents the next generation of web scraping tools, combining the power of AI with the flexibility of graph-based approaches to create a solution that’s both powerful and sustainable. Whether you’re a solo developer or part of an enterprise team, ScrapeGraphAI offers capabilities that significantly advance what’s possible in automated data extraction.

